Контент-пайплайн Khabaroff.Studio превращает 10 лет заметок в публикуемые статьи за минуты. Архитектура: 4 параллельных источника данных (Linear, записи встреч, база знаний в Obsidian, веб-исследование) → AI-генерация черновика → редакторский слой. Черновик за 5 минут, готовая статья за час.
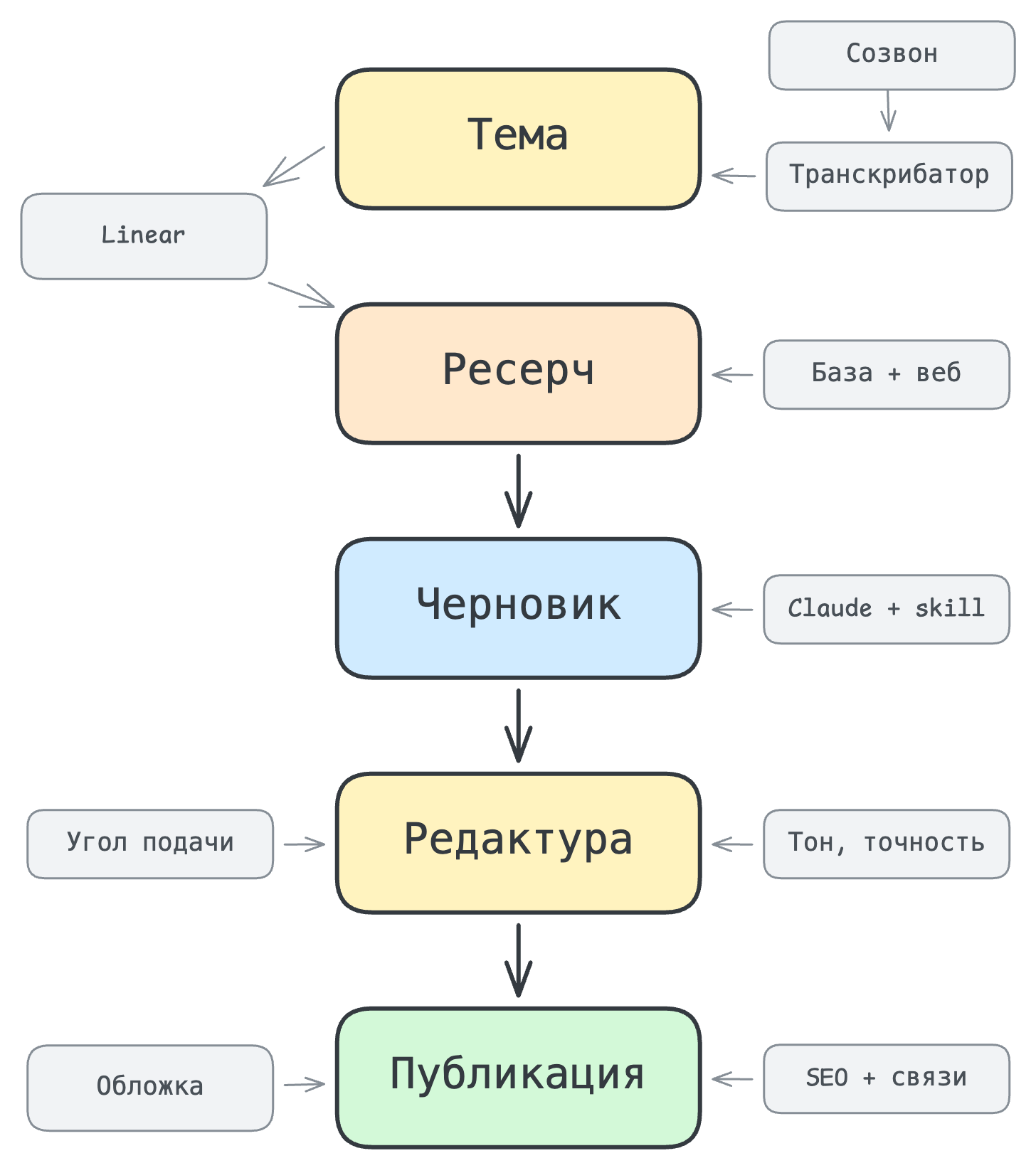
Мы публикуем статьи в блог студии. Со стороны выглядит просто: текст, обложка, опубликовано. Изнутри — это несколько параллельных процессов, которые запускаются задолго до того, как кто-то сядет писать. Когда приходит момент написания — большая часть работы уже сделана. Остается собрать, отредактировать и опубликовать.
Вот как это устроено.
| Этап | Вход | Выход | Инструмент |
|---|---|---|---|
| Извлечение тем | Записи созвонов | Задачи с контекстом | Транскрибатор → Linear |
| Сбор контекста | Задача в Linear | 4 файла контекста | MCP: Linear, vault, web search |
| Генерация обложки | Команда в терминале | SVG-обложка | Node.js генератор (детерминированный) |
| Черновик | 4 файла контекста + промт | Текст 1000-2000 слов | Claude + стиль-гайд |
| Редактура | Черновик | Готовая статья | Человек: угол, тон, факты |
Обложки: 2 дня → 3 секунды
Два дня я занимался только обложками. Не генерировал их — проектировал систему, которая будет их генерировать.
От ручных эскизов к детерминированному генератору
Сначала я нарисовал несколько обложек вручную. Круги, линии-связи между ними, крупные квадраты как акценты. Три цвета: черный, белый, серый. Никаких стоковых метафор, никаких фотографий — чистая геометрия. Когда стало понятно, что работает визуально, я описал это словами: какие элементы, какие размеры, какие расстояния между узлами, где можно обрезать квадрат краем холста, а где нельзя, какая зона зарезервирована под текст.
Это описание стало промтом для Claude — не «нарисуй картинку», а «напиши скрипт, который генерирует SVG по этим правилам». Два дня ушли на итерации: первые версии скрипта рисовали хаос, связи налезали друг на друга, акцентные узлы оказывались в углу. Я уточнял правила: минимальное расстояние между узлами — 60 пикселей, максимум 4 связи на узел, вероятность связи — 55% (чтобы были естественные разрывы), акцентные узлы не ставить в нижний правый угол.
К концу второго дня получился детерминированный генератор. Не нейросеть — обычный скрипт на Node.js. Он раскидывает 18-35 узлов по холсту, проводит между ними связи, ставит 1-2 крупных квадрата и анимирует все это: квадраты медленно плывут по орбите, связи прорисовываются одна за другой, узлы появляются с затуханием.
Теперь, когда выходит новая статья — одна команда в терминале, 3 секунды, готовая обложка. Можно сгенерировать 1000 штук за минуту и выбрать. Каждая уникальна, но все выдержаны в одном стиле, потому что стиль зашит в код, а не в голову дизайнера.
Красота в том, что мы с Claude спроектировали автоматизацию, которая теперь работает детерминированно. Вкус — штука ощущенческая, мутная, плохо формализуемая. Но из этой мутной системы «мне нравится вот так, а вот так — нет» появился скрипт, который не ошибается в 95% случаев. Разрозненные ощущения превратились в набор правил: расстояния, вероятности, зоны, палитра. То, что раньше требовало дизайнера с насмотренностью, теперь выполняет 200 строк кода.
Но эти 3 секунды стоят на фундаменте из двух дней: от ручных эскизов через описание правил к работающему скрипту.
Темы: не придумываем — извлекаем
Темы для статей не рождаются на брейнштормах. Они всплывают на рабочих созвонах — еженедельных синках команды.
Как это выглядит: Сергей показывает, что в настройках Telegram-бота есть неприметная галочка «прием платежей». Максим удивляется: «Прямо форма, которую сам Telegram предоставляет. Ух ты.» Дима тут же спрашивает про валидацию. Мы понимаем, что здесь есть статья, и добавляем пару фраз контекста прямо на созвоне — чтобы транскрибатор потом это подхватил.
Или другой случай: кто-то рассказывает, как записал трехминутное видео конкурентского бота, нарезал на кадры и скормил Claude — и получил готовую схему переходов в Excalidraw. Команда обсуждает, пробует, понимает, что это работает. Фиксируем: еще одна тема.
Как транскрибатор извлекает темы
Все встречи записываются. После созвона запись проходит через транскрибатор, который делает две вещи. Первая — само собой разумеющаяся: задачи прилетают в Linear. Вторая — менее очевидная: транскрибатор извлекает потенциальные темы для блога, которые прозвучали на встрече. Не просто заголовки, а с контекстом: кто предложил идею, на каком таймкоде, какие цитаты прозвучали, какая была реакция коллег. Тема фиксируется в задаче с предварительной структурой поста и ссылкой на запись.
Вот что здесь важно: люди дают уникальный вклад — своими мозгами, своим контекстом, жизненным опытом. Никакой пайплайн не придумает тему «10% комиссия Telegram — это гениально», потому что для этого нужно было самому подключать платежи и удивиться тому, как это просто. Тема рождается из прожитого опыта, а не из анализа ключевых слов.
Статья пишется не из головы — она пишется из опыта, который уже случился и был зафиксирован.
Контекст: параллельный сбор из четырех источников
Когда тема выбрана и задача создана, начинается сбор контекста. Это не ручной процесс — пайплайн запускает четыре параллельных поиска и сохраняет результаты в рабочую папку.
Источник 1: Linear. Из задачи извлекается все, что там накоплено: описание, предварительная структура поста, ключевые тезисы, ссылки на встречи. Это каркас — основная идея и угол подачи, на который потом нанизывается все остальное.
Источник 2: Записи встреч. Из транскриптов созвонов вытаскиваются фрагменты, относящиеся к теме. Конкретные цитаты участников, реакции, контраргументы, уточнения. Эти цитаты — живой голос команды, который потом попадает в текст. Не пересказ, а дословные фразы.
Источник 3: База знаний. У Сергея в Obsidian около 5000 статей и заметок, накопленных за 10 лет. Два месяца эта база приводилась в порядок: размечались типы, проставлялись теги, создавались карточки людей и концепций, выстраивались связи между материалами. Отдельный пайплайн поддерживает базу в актуальном состоянии — она обновляется сама, но об этом как-нибудь в другой раз. Важно, что эта база работает и для людей, и для агентов: на ее основе пишутся статьи, готовятся лекции и семинары, выстраиваются связи между идеями, которые иначе остались бы разрозненными.
Поиск по базе работает через qmd — инструмент, который комбинирует BM25, векторный поиск и LLM-реранкинг. Не просто «найди слово в файле», а семантический поиск по смыслу: запрос «монетизация через ботов» найдет статью про Telegram-платежи, даже если в ней нет слова «монетизация».
Когда пайплайн ищет контекст для статьи — он обращается к этой базе. Пишем про платежи в Telegram — находятся статьи про ботов, про Telegram API, про подходы к монетизации. Это помогает не повторяться и находить связи, которые вручную легко пропустить.
Источник 4: Веб. Поиск по интернету идет в несколько слоев. Brave Search — быстрый поиск по фактам, новостям, свежим данным. Exa — семантический поиск, который находит концептуально похожие материалы, а не просто совпадения по ключевым словам. Perplexity — синтез: задаешь сложный вопрос, получаешь сводку с источниками. Все три работают параллельно через MCP-серверы и API, результаты объединяются. Для скачивания найденных страниц — Jina Reader (основной) и Firecrawl (запасной). Это не для копирования — это для понимания, где проходит граница известного. Если все уже написали «как подключить платежи в Telegram» — нам нужен другой угол.
Четыре файла контекста ложатся в рабочую папку рядом с черновиком. Вместе они дают полную картину: что мы знаем сами (встречи, база), что знает рынок (веб), и в каком направлении двигаться (задача в Linear).
Черновик: 5 минут — но после 10 лет
Когда контекст собран, Claude получает все это как входные данные и генерирует черновик. Пять минут — и есть текст с цитатами из встреч, ссылками на исследования, конкретными примерами из нашего опыта.
Три слоя подготовки
Но за этими пятью минутами стоят три слоя подготовки.
Первый слой — годы накопления контекста. База знаний не появляется за ночь. Около 5000 статей и заметок за 10 лет, размеченные карточки людей и концепций, структура тегов — это результат систематической работы. Два месяца база приводилась в порядок, и теперь каждая входящая статья проходит через пайплайн автоматически: скачивание, генерация краткого содержания, извлечение упоминаний людей и концепций, классификация, связывание с другими материалами. Без этой базы поиск по vault вернул бы пустоту.
Второй слой — дни настройки пайплайна. Сам процесс сбора контекста из четырех источников — это код, промты, инструкции, обработка ошибок. Настроить, чтобы поиск по встречам находил релевантные фрагменты, чтобы веб-исследование не скатывалось в пересказ первой страницы выдачи, чтобы контекст из Linear извлекался в правильном формате — на это ушло еще два дня.
Третий слой — промт для черновика. Отдельная инструкция, которая объясняет Claude, как из четырех файлов контекста собрать связный текст. Какой стиль, какой объем, как использовать цитаты, как не скатиться в общие слова. Этот промт тоже итерировался десятки раз.
Без любого из этих слоев генерация выдает общие слова. С ними — конкретный текст, который читается как написанный человеком, который глубоко в теме. Потому что контекст и есть глубина.
Где остается человек
Не везде. И это осознанный выбор.
Что не автоматизируется
Исходный материал — человек. Извлечение тем из встреч происходит автоматически — транскрибатор сам находит потенциальные заготовки для статей. Но чтобы ему было что находить, нужен человек, который на созвоне расскажет про свой опыт, поделится находкой, выскажет мнение, которое он вынашивал годами. Осознать, что что-то важное, отсортировать в своем понимании, вытащить из своего контекста и сформулировать — это работа, которую делает только человек.
Угол подачи — человек. Одна и та же тема — «платежи в Telegram» — может стать инструкцией, аналитикой, историей провала или историей находки. Выбор угла определяет, будет ли статья скучной или запоминающейся. Это решение принимает автор, а не генерация.
Редактура — человек. Черновик — это 80% текста. Оставшиеся 20% — тон, ритм, точность формулировок, удаление воды, усиление ключевых мыслей. Автоматически сгенерированный текст почти всегда нуждается в том, чтобы его сделали резче, короче и честнее.
Финальное решение — человек. Публиковать, переписать или выбросить. Транскрибатор намеренно настроен так, чтобы не пропускать ничего — он должен найти все, что может стать заготовкой статьи. Это не баг, это фича: лучше вытащить десять тем и три выбросить, чем пропустить одну сильную. Но иногда робот вытягивает тему, которая на бумаге выглядит нормально, а при развертывании оказывается пустой — высосанной из пальца. Бывает обидно выбрасывать черновик, на который уже потрачено время. Но именно здесь нужен человек: почувствовать, что не клеится, и остановиться.
Все остальное автоматизировано: сбор данных из четырех источников, генерация вариантов обложек, сборка контекста, формирование первого черновика. Это работа, которая раньше занимала часы, но не требовала творчества. Именно такую работу имеет смысл отдавать машине.
Частые вопросы
Какой стек используется для контент-пайплайна?
Claude Code для генерации черновиков, Node.js для обложек, qmd (BM25 + vector + LLM reranking) для поиска по базе знаний, Brave/Exa/Perplexity для веб-исследования. Все связано через MCP-серверы.
Сколько времени занимает подготовка одной статьи?
Черновик — 5 минут. Редактура — 40 минут. Итого час. Но за этим стоят дни настройки пайплайна и годы накопления базы знаний из 5000 заметок.
Можно ли повторить такой пайплайн для своего блога?
Да, если есть накопленный контекст. Пайплайн без базы знаний выдает generic тексты. Начните с систематического сбора заметок — это фундамент, на котором все работает.
Итог
Готовая для публикации статья появляется за час. Черновик — за 5 минут. Оставшиеся 40 минут — редактура: угол подачи, тон, точность формулировок, перекрестные ссылки на другие материалы. И публикация.
Но этот час стоит на фундаменте, который строился днями и годами:
- 2 дня на промт обложек → теперь 3 секунды на обложку
- 2 дня на настройку пайплайн контекста → теперь 5 минут на сбор из четырех источников
- Годы на накопление базы знаний → теперь есть откуда брать контекст для любой темы
- Еженедельные созвоны → постоянный поток тем с живыми историями
Самое интересное, что при таком подходе можно выделить блок времени — скажем, два-три часа — и за одну сессию подготовить сразу несколько статей. С перекрестными ссылками друг на друга, с общей логикой, с единым контекстом. А потом публиковать по расписанию. Раньше одна статья занимала неделю. Теперь за то же время можно выпустить серию.
1000 обложек за минуту. Черновик за 5 минут. Но это не скорость — это сжатие. Вся подготовка, которая раньше размазывалась на дни и недели, упакована в инструменты, промты и базу, которые работают мгновенно. Автоматизация не сокращает путь — она сжимает его в точку, к которой ты долго шел.
